
The Extraction module in Supplier Data Manager (SDM) automatically enriches missing product attributes by analyzing text and asset sources such as product descriptions, titles, and other fields. It lets you unlock structured information that was previously buried in unstructured text — dimensions, materials, technical specifications — and fills it directly into your product records.
Why use the Extraction module
- Save time: Reduce manual data entry by letting the AI scan and extract data from text attributes automatically.
- Improve data quality: Minimize errors and inconsistencies by relying on automated extraction rather than manual copy-paste.
- Speed up onboarding: Get new supplier products into your catalog faster with richer, more complete product data from the first import.
How the Extraction module works
When a job reaches the Extraction module in SDM, the AI analyzes the content of the configured source fields (for example, product descriptions or titles) and fills in the target attributes. If the AI's confidence in a predicted value is low, the attribute is flagged for manual review. Attributes filled by the AI are marked with a bot icon so you can distinguish them from manually entered values.
For products that share identical source content, extraction is performed only once. This avoids duplicate processing and reduces AI workload.
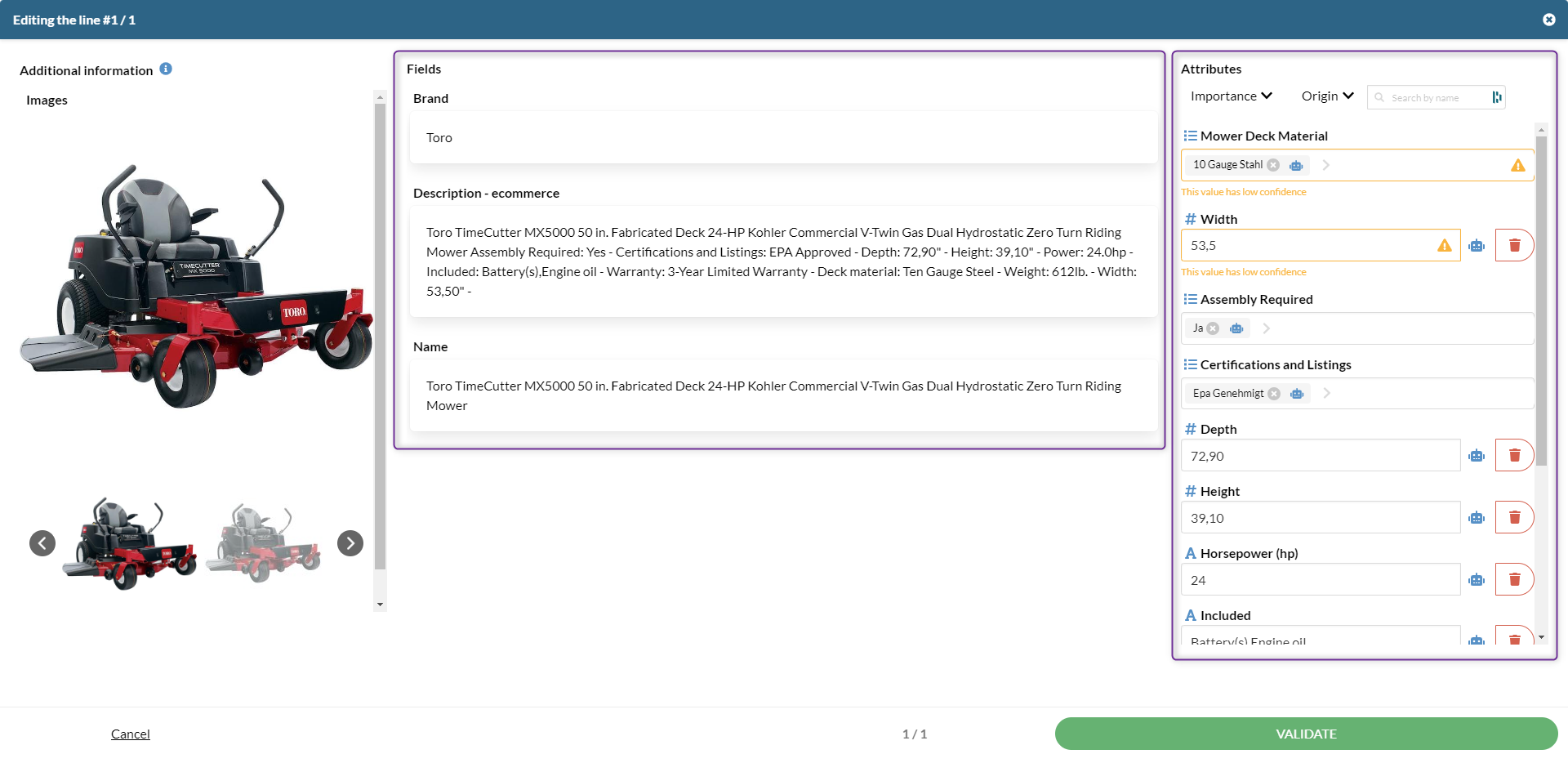
The screenshot above shows the Extraction module interface with the three-column layout: left column displaying additional product information, center column showing the source fields used by the AI, and right column showing the target attributes to be filled.
Understanding the Extraction module interface
The Extraction module interface in SDM is divided into three columns:
- Left column — Displays additional product information for reference (for example, a product image from the input file). This content is not used directly by the AI model but helps you confirm or edit extracted values.
- Center column — Shows the source fields the AI uses to generate predictions (for example, a long-form product description).
- Right column — Contains the target attributes that need to be filled. Attributes completed by the AI are marked with a bot icon.
Attribute types
- Select attributes — Predefined values you select from a list. The AI picks the closest matching option from the available choices.
- Textual attributes — Free-text or numeric fields. You can accept the AI's suggestion or enter a value manually.
Attribute statuses
Attributes in the right column are color-coded based on their requirement level:
- Mandatory (red star) — Must be filled before moving to the next step.
- Important (orange dot) — Alerts you if the field is empty, but does not block progress.
- Optional — Non-blocking and not represented visually.
Requirement levels are configured by your SDM administrator. For details, see Requirement levels in SDM.
Filters
Use the filters in the right column to focus your review:
- Origin filter — Filter attributes by how their value was set:
-
Previously filled — The field already had a value at the start of the Extraction step. These fields may be overwritten if the step is configured with
replace_existingenabled. - Model — The value was filled by the AI, extracted from the configured source fields.
- User created — The field was empty and you filled it manually.
- User modified — The AI filled the field, but you subsequently edited it.
- Empty — The field has no value yet.
- Importance filter — Filter attributes by requirement level: mandatory, important, or optional.
Configure data sources for the Extraction module
The Extraction module can analyze different types of text and asset sources to enrich product attributes. You can configure which sources the AI uses directly in SDM.
To change the source fields:
- In SDM, go to Workflow > Settings > Steps.
- Select the Extraction step you want to customize.
- In the Sources section, choose the attributes you want the AI to analyze.
Select fields that are well-maintained and rich in useful information (titles, descriptions, feature lists). The more detailed and cleaner the source content, the better the AI will perform.
Image assets can also be used as sources, provided they are of type media (image URL assets are not supported).
For more details on managing AI sources, see AI agent.
Row grouping and deduplication
If the Extraction step shows fewer rows than other steps in the workflow, it is because products with identical values across all source fields are automatically grouped and processed as a single row. This avoids redundant processing and reduces AI workload. All grouped products receive the same extracted values.
Limitations
Keep the following limits in mind when using the Extraction module in SDM:
- Maximum products (rows) per job: 30,000 rows.
- Recommended maximum source attributes: 50 — using more than 50 source attributes may reduce extraction accuracy.
For best results, test with smaller batches (fewer than 200 products and under 20 source attributes) before scaling up. This makes it easier to review extracted data and adjust your configuration if needed.
Related
- AI agent — Learn how the AI model works and how to write custom prompts.
- Modules overview — Overview of all SDM modules and how to combine them.
- Extraction administration — Admin guide for configuring Extraction step parameters (admin access required).
- Requirement levels in SDM — How mandatory, important, and optional levels are configured and used.